데이터의 구조
1. LONG DATA (Tidy data)
- 하나의 속성이 하나의 컬럼으로 정의되어 값들이 여러 행으로 쌓이는 구조
- RDBMS의 테이블 설계 방식
- 다른 테이블과의 조인 연산이 가능한 구조

2. WIDE DATA (Cross table)
- 행과 컬럼에 유의미한 정보 전달을 목적으로 작성하는 교차표
- 하나의 속성값이 여러 컬럼으로 분리되어 표현
- RDBMS에서 WIDE 형식으로 테이블 설계 시 값이 추가될 때마다 컬럼이 추가돼야 하므로 비효율적!
- 다른 테이블과의 조인 연산이 불가함
- 주로 데이터를 요약할 목적으로 사용
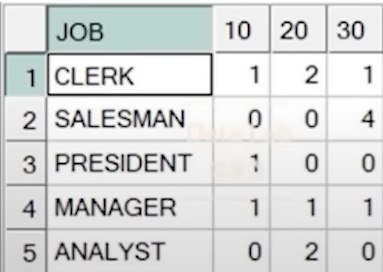
- 하나의 관찰대상 (속성)을 한 컬럼으로 정의하지 않고 값의 종류별로 컬럼을 분리
PIVOT
- 교차표를 만드는 기능
- LONG 데이터를 WIDE 데이터로
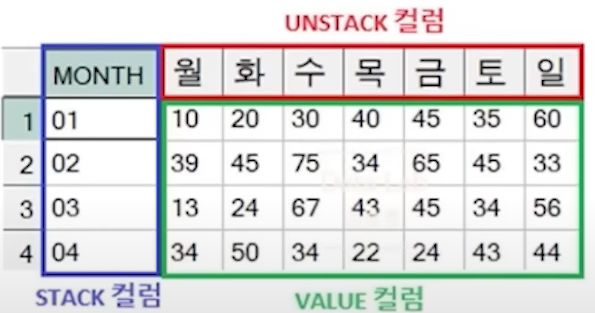
- STACK 컬럼, UNSTACK 컬럼, VALUE 컬럼의 정의가 중요!
- FROM 절에 STACK, UNSTACK, VALUE 컬럼명만 정의
- 필요 시 서브쿼리 사용하여 필요 컬럼 제한
- PIVOT 절에 UNSTACK, VALUE 컬럼명 정의
- PIVOT 절 IN 연산자에 UNSTACK 컬럼 값을 정의
- FROM 절에 선언된 컬럼 중 PIVOT 절에서 선언한 VALUE 컬럼 UNSTACK 컬럼을 제외한 모든 컬럼은 STACK 컬럼이 됨
** 문법

- 반드시 FROM절에 STACK 컬럼, UNSTACK 컬럼, VALUE 컬럼 모두 명시 !
예1) EMP 테이블에서 JOB별 DEPTNO별 도수(COUNT) 출력


주의) FROM 절 서브쿼리 안에 JOB이 없으면 그냥 부서별로의 도수가 출력됨

주의) FROM 절에 서브쿼리로 컬럼을 제한하지 않아 컬럼이 많으면 STACK 컬럼이 많아짐!

예2) 다음의 테이블에서 성별, 연도별 구매량 총 합을 표현하는 교차로 작성

UNPIVOT
- WIDE 데이터를 LONG 데이터로 변경하는 문법
- STACK 컬럼 : 이미 UNSTACK 되어 있는 여러 컬럼을 하나의 컬럼으로 STACK 시 새로 만들 컬럼 이름 (사용자 정의)
- VALUE 컬럼 : 교차표에서 셀 자리 (VALUE)값을 하나의 컬럼으로 표현하고자 할 때 새로 만들 컬럼명 (사용자 정의)
- 값 1, 값 2, ... : 실제 UNSTACK 되어 있는 컬럼 이름들

** 문법

예1) STACK_TSET PIVOT 결과가 STACK_TEST 테이블에 저장되어 있을 때, 다시 STACK_TEST 테이블 값을 UNSTACK_TEST 형태로 변경 (STACK 처리)

- UNSTACK 데이터의 컬럼 명이 숫자라면 컬럼명은 문자로 저장되므로 쌍따옴표 전달 필수!
- IN ("2008", "2009")
예2) 아래 테이블 생성 후 STACK 처리


- UNPIVOT 컬럼명이 숫자가 아닌 문자인 경우 IN 뒤에 쌍따옴표 전달 X
'sqld' 카테고리의 다른 글
| 2-17) DML (0) | 2024.08.23 |
|---|---|
| 2-16) 정규 표현식 (0) | 2024.08.22 |
| 2-14) 계층형 질의 (0) | 2024.08.22 |
| 2-13) TOP N QUERY (0) | 2024.08.22 |
| 2-12) 윈도우 함수 (0) | 2024.08.22 |



