정규 표현식
- 문자열의 공통된 규칙을 보다 일반화하여 표현하는 방법
- 정규 표현식 사용 가능한 문자함수 제공 (REGEXP_REPLACE, REGEXP_SUBSTR, REGEXP_INSTR,...)
- 예) 숫자를 포함하는, 숫자로 시작하는 4자리, 두 번째 자리가 A인 5글자 등 표현
예) 일반화 규칙 찾아내기
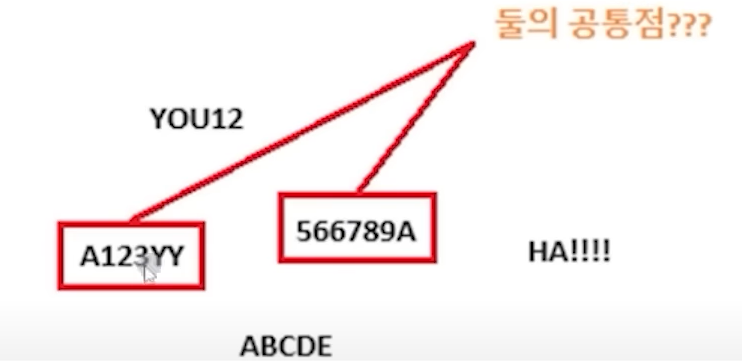
- '숫자를 연속적으로 3개 이상 포함하는' 이라는 공통 패턴을 발견하여 표현할 수 있음
정규 표현식 종류

- []는 안에 어떤 것이 들어가든 한 글자를 나타냄
- ^a는 원래 'a로 시작하는'
- [^a] 로 [] 안에 들어가면 a를 제외한 모든 문자를 나타냄
- a{2} : aa
예) 전화번호의 일반화

- 전화번호는 숫자와 -로 구성 : [0-9-]+ → (0-9- : 숫자 or -) (+ : 1개 이상)
- tel 값은 동시에 있고 )가 있는 경우와 없는 경우를 모두 표현 : tel\)? → )를 표현하기 위해 \ 붙임
REGEXP_REPLACE
- 정규식 표현을 사용한 문자열 치환
** 문법
REGEXP_REPLACE(대상, 찾을 문자열, [바꿀 문자열], [검색 위치], [발견 횟수], [옵션])
** 특징
- 바꿀 문자열 생략 시 : 문자열 삭제
- 검색 위치 생략 시 : 1
- 발견 횟수 생략 시 : 0 (모두 치환/삭제)
** 옵션
- c : 대소를 구분하여 검색
- i : 대소를 구분하지 않고 검색
- m : 패턴을 다중라인으로 선언 가능
예1) ID에서 숫자 삭제

- \d , [:digit:] : 숫자
- '' (빈문자열)로 설정하면 바꿀 문자열 없음 → 찾은 문자열 삭제
예2) ID에서 특수기호 삭제

- '\W' : 특수기호 (_ 미포함)와 공백 ( ↔ '\w' : _를 포함한 문자와 숫자)
- '\W|_' : _를 포함한 특수기호
- [:funct:] : 특수기호
예3) PROFESSOR 테이블의 ID에서 문자와 문자 바로 뒤에 오는 숫자를 삭제 (대소구분 X)
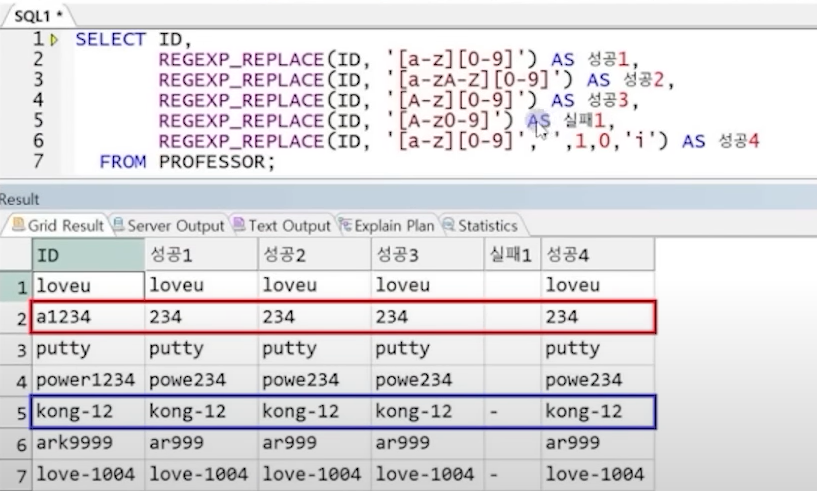
- REGEXP_REPLACE(ID, '[A-z][0-9]', '', 1, 0, 'i') 로 옵션까지 모두 설정하거나 뒤를 모두 기술하지 않고 기본값으로
- '[A-z0-9]' 로 전달할 경우 문자와 숫자를 모두 삭제하므로 특수문자(-) 제외 모두 삭제됨
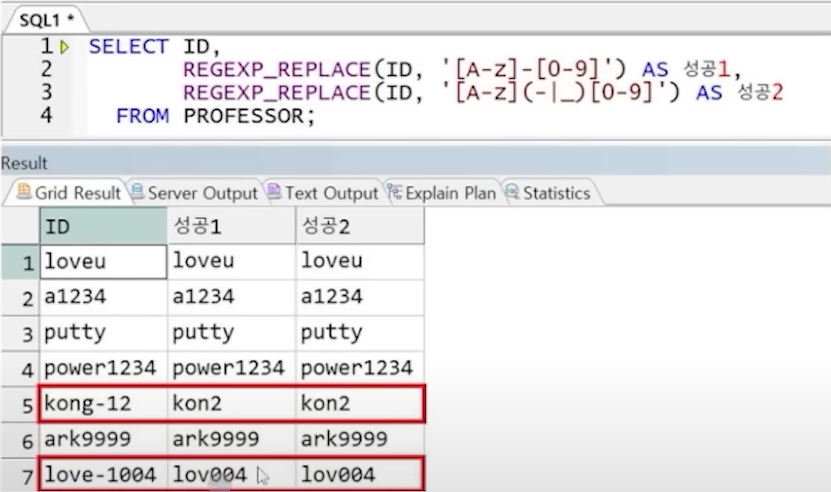
예4) kong-12에서 g-1을 지우는 방법 (문자-숫자 지우기)
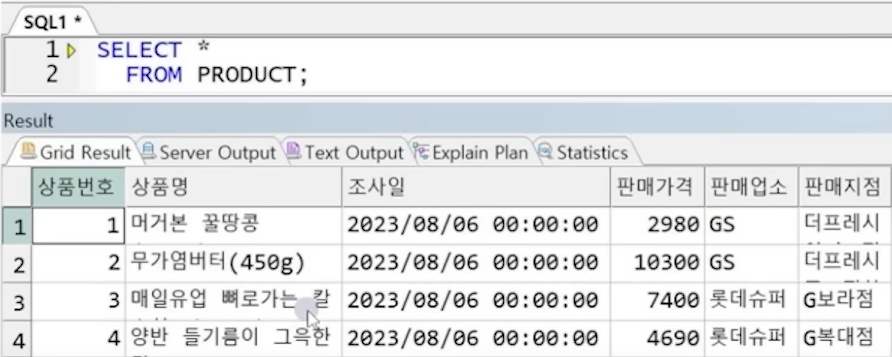
예5) PRODUCT 테이블의 상품명에서 괄호 포함, 괄호 안에 들어가는 모든 글자를 삭제
테이블 데이터)
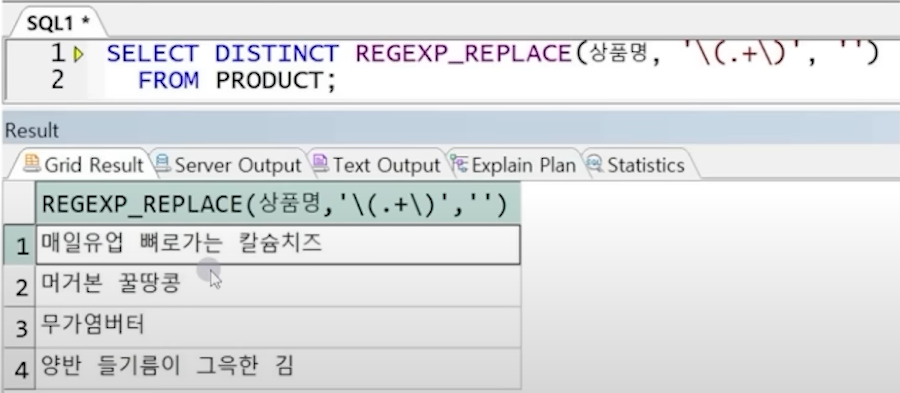
- 괄호를 표현하기 위해서는 \(로 전달
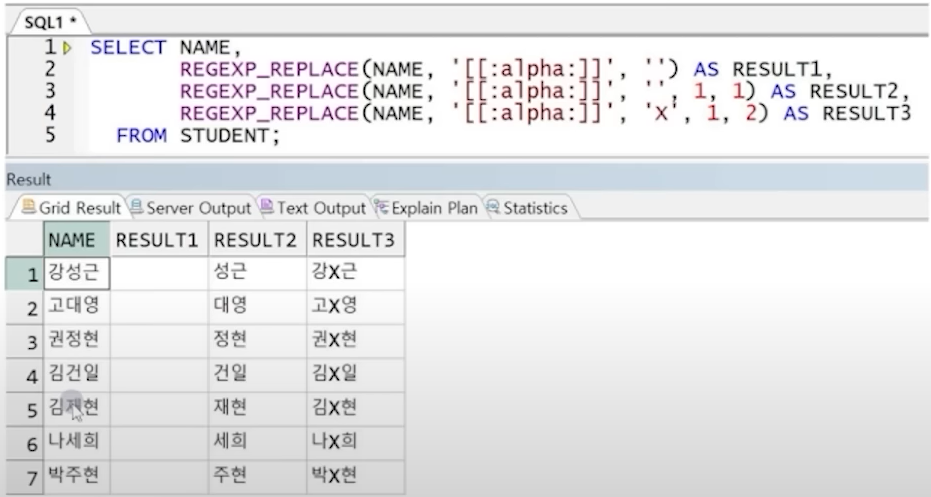
예6) REGEXP_REPLACE를 사용하여 두 번째 발견된 문자 값을 X로 치환
REGEXP_SUBSTR
- 정규식 표현식을 사용한 문자열 추출
- 옵션은 REGEXP_REPLACE와 동일
** 문법
REGEXP_SUBSTR(대상, 패턴, [검색 위치], [발견 횟수], [옵션], [추출 그룹])
** 특징
- 검색 위치 생략 시 : 1
- 발견 횟수 생략 시 : 1 (첫 번째 발견된 문자열 추출)
- 추출 그룹은 서브 패턴을 추출 시 그 중 추출할 서브패턴 번호
예1) 전화번호를 분리하여 지역번호 추출

- 숫자여러개 + ) + 숫자여러개 + - + 숫자여러개
- \d+, \), \d+, -, \d+
- ()로 그룹 나눠 첫 번째 그룹 추출
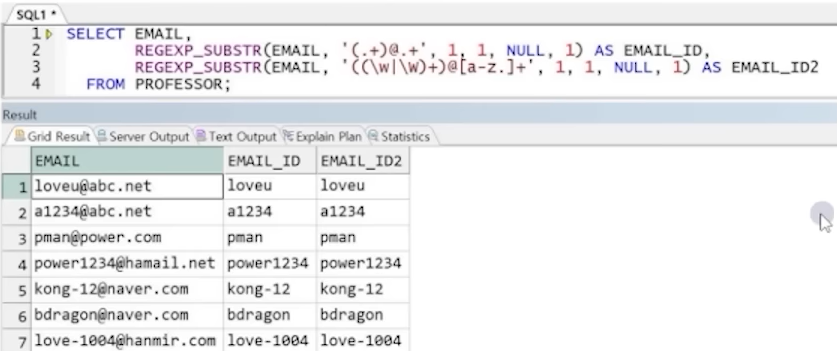
예2) 이메일 아이디 추출 (서브패턴 활용)
REGEXP_INSTR
- 주어진 문자열에서 특정 패턴의 시작 위치를 반환
- 옵션은 REGEXP_SUBSTR과 동일
** 문법
REGEXP_INSTR(원본, 찾을 문자열, [시작 위치], [발견 횟수], [옵션])
** 특징
- 시작 위치 생략 시 : 1 (처음부터)
- 발견 횟수 생략 시 : 1 (처음 발견된 문자열 위치 리턴)
예1) ID 값에서 두 번째 발견된 숫자의 위치

- \d 는 뒤에 횟수를 지정하지 않으면 한 자리 수의 숫자를 의미
예2) 정규식 표현식을 사용한 패턴에 일치하는 n 번째 문자열 위치

- [^ ] : 공백을 제외한 모든 문자
- [^ ]+ 공백을 제외한 모든 문자가 1개 이상 → 단어
- 2 번째 단어 찾기 → ORACLE → 시작 위치 : 5
REGEXP_LIKE
- 주어진 문자열에서 특정 패턴을 갖는 경우 반환
- WHERE 절에서만 사용 가능
- 옵션은 REGEXP_REPLACE와 동일
** 문법
REGEXP_LIKE(원본, 찾을 문자열, [옵션])
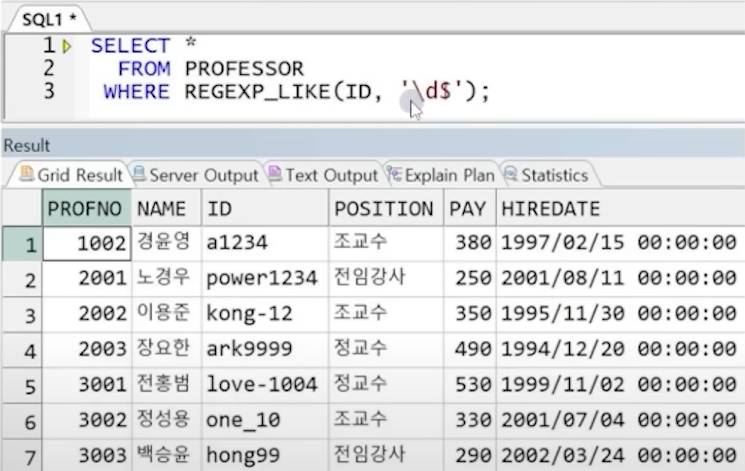
예) ID 값이 숫자로 끝나는 교수 정보 출력
REGEXP_COUNT
- 주어진 문자열에서 특정 패턴의 횟수를 반환
- 옵션은 REGEXP_REPLACE와 동일
** 문법
REGEXP_COUNT(대상, 찾을 문자열, [옵션])
예) ID 값에서의 숫자의 수

- \d는 한 자리 수의 숫자, \d+는 연속적인 숫자를 의미
- \d+로 전달 시 연속적인 숫자를 1개로 취급
'sqld' 카테고리의 다른 글
| 2-18) TCL (0) | 2024.08.23 |
|---|---|
| 2-17) DML (0) | 2024.08.23 |
| 2-15) PIVOT과 UNPIVOT (0) | 2024.08.22 |
| 2-14) 계층형 질의 (0) | 2024.08.22 |
| 2-13) TOP N QUERY (0) | 2024.08.22 |



